
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- col_names
- 부스트캠프aitech3기
- 부스트캠프
- group_by( )
- Filter
- LinearNeuralNetwork
- JavaScript
- mutate( )
- dplyr
- convolution 역전파
- 역전파알고리즘
- 자바스크립트
- r
- Multi-Layer Perceptron
- Convolution
- regular expression
- 생활코딩
- 부스트캠프 aitech3기
- Beyond Linear Neural Networks
- 정규표현식
- regex
- RNN
- aitech
- Sequential Model
- NomadCoder
- 네이버커넥트재단
- summarise( )
- 베이즈통계학
- 모각공
- 네이버커넥트
- Today
- Total
목록전체 글 (52)
clear_uncertainty
 R - R언어 dplyr로 데이터 전처리하기 ( mutate( ), group_by( ), summarise( ) )
R - R언어 dplyr로 데이터 전처리하기 ( mutate( ), group_by( ), summarise( ) )
이번 포스트에서는 R언어로 데이터 전처리하는 방법에 대해 서술하겠습니다. '데이터 전처리(Data Preprocessing)'은 분석에 적합하게 데이터를 가공하는 작업입니다. 일부를 추출하거나, 종류별로 나누거나 여러 데이터를 합치는 등 데이터를 자유롭게 가공할 수 있어야 목적에 맞게 분석할 수 있습니다. dplyr은 데이터 전처리 작업에 가장 많이 사용되는 패키지입니다. dplyr의 대표적인 함수를 정리하면 아래와 같습니다. dplyr 함수 기능 filter( ) 행추출, 2023.01.12 - [언어/R] - R - R언어 dplyr로 데이터 전처리하기 (filter( ), %>%, %in%) select( ) 열 추출, 2023.01.12 - [언어/R] - R - R언어 dplyr 함수로 데이터 ..
 R - R언어 dplyr 함수로 데이터 전처리 하기 (select( ) , arrange( ), desc( ))
R - R언어 dplyr 함수로 데이터 전처리 하기 (select( ) , arrange( ), desc( ))
이번 포스트에서는 R언어로 데이터 전처리하는 방법에 대해 서술하겠습니다. '데이터 전처리(Data Preprocessing)'은 분석에 적합하게 데이터를 가공하는 작업입니다. 일부를 추출하거나, 종류별로 나누거나 여러 데이터를 합치는 등 데이터를 자유롭게 가공할 수 있어야 목적에 맞게 분석할 수 있습니다. dplyr은 데이터 전처리 작업에 가장 많이 사용되는 패키지입니다. dplyr의 대표적인 함수를 정리하면 아래와 같습니다. dplyr 함수 기능 filter( ) 행추출, 2023.01.12 - [언어/R] - R - R언어 dplyr로 데이터 전처리하기 (filter( ), %>%, %in%) select( ) 열 추출 arrange( ) 정렬 mutate( ) 변수 추가 summarise( ) 통계..
 R - R언어 dplyr로 데이터 전처리하기 (filter( ), %>%, %in%)
R - R언어 dplyr로 데이터 전처리하기 (filter( ), %>%, %in%)
이번 포스트에서는 R언어로 데이터 전처리하는 방법에 대해 서술하겠습니다. '데이터 전처리(Data Preprocessing)'은 분석에 적합하게 데이터를 가공하는 작업입니다. 일부를 추출하거나, 종류별로 나누거나 여러 데이터를 합치는 등 데이터를 자유롭게 가공할 수 있어야 목적에 맞게 분석할 수 있습니다. dplyr은 데이터 전처리 작업에 가장 많이 사용되는 패키지입니다. dplyr의 대표적인 함수를 정리하면 아래와 같습니다. dplyr 함수 기능 filter( ) 행추출 select( ) 열 추출 arrange( ) 정렬 mutate( ) 변수 추가 summarise( ) 통계치 산출 group_by( ) 집단별로 나누기 left_join( ) 데이터 합치기(열) bind_rows( ) 데이터 합치기(..
 R - R언어로 파생변수만들기(조건문 ifelse, 중첩조건문 ifelse, hist, table, qplot)
R - R언어로 파생변수만들기(조건문 ifelse, 중첩조건문 ifelse, hist, table, qplot)
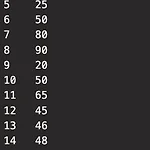
이번 포스트에서는 R언어로 파생변수를 만드는 것에 대해 서술하겠습니다. 변수를 조합하거나 함수를 적용해 새 변수를 만들어 분석할 수 있습니다. 파생변수란 기존의 변수를 조합하여 새로운 변수를 만들어 내는 것을 의미합니다. 사용자가 특정 조건을 만족하거나 특정 함수에 의해 값을 만들어 의미를 부여하는 변수로 매우 주관적일 수 있으므로 논리적 타당성을 갖출 필요가 있습니다. 특정상황에만 의미성 부여가 아닌 보편적이고 전 데이터구간에 대표성을 가지는 파생변수 생성을 위해서 노력해야 합니다. 세분화 고객행동예측, 캠페인반응예측 등에 활용할 수 있습니다. 활용에 실습하기 위해 ggplot2 패키지에 내장된 mpg 데이터를 이용해보겠습니다. head를 통해 mpg를 보니, 많은 열과 몇개가 끝인지 모르는 행이 있습..
 R - R언어로 데이터 파악하기 (head, tail, View, dim, str, summary)
R - R언어로 데이터 파악하기 (head, tail, View, dim, str, summary)
이번 포스트에서는 R언어로 데이터를 파악하는 함수에 대해 알아보겠습니다. head() head() 함수는 데이터 앞부분 파악할 슈 있는 함수입니다. 너무 많은 데이터의 내용을 확인하려면 화면에 너무 많은 내용이 출력되기때문에 알아보기 어렵습니다. head() 는 데이터의 앞부분을 출력합니다 위와 같은 입력에서는 exam의 아래와 같이 데이터 20행까지 모두 출력합니다. head() 함수를 사용하면 앞의 6개만 출력됩니다. 만약 6개가 아닌 3개만을 출력하고 싶다면 아래와 같이 괄호 안에 3을 입력해주면됩니다. tail( ) tail()은 head와 비슷하지만 데이터의 뒷부분을 출력하는 기능을 합니다. 괄호 안에 데이터 프레임을 입력하면 뒤에서부터 여섯 행을 출력합니다. head()와 동일하게 괄호 안에 ..
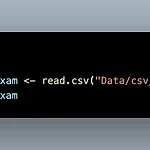
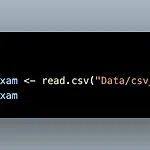 R - CSV, RDS 불러오기 + 저장하기 (read.csv, write.csv, saveRDS, readRDS)
R - CSV, RDS 불러오기 + 저장하기 (read.csv, write.csv, saveRDS, readRDS)
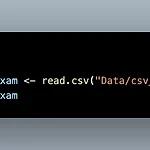
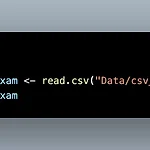
CSV 파일은 Comma-separated Values라는 이름으로 쉼표로 구분되어 있는 형태입니다. 엑셀 파일에 비해 용량이 작기때문에 데이터를 주고받을 때 CSV 파일을 자주 이용합니다. read.csv()를 통해 csv 파일을 불러올 수 있습니다. 마찬가지로 괄호 안에는 ""와 함께 경로를 입력합니다. excel의 첫번째 행이 변수가 아닐 때 col_names = F를 통해 첫번째 행을 데이터로 인식했습니다. CSV에서는 col_names 와 같은 역할을 하는 것이 header입니다. 그러므로 CSV의 첫번째 행이 변수가 아닐 때 header = F를 통해 첫번째 행을 데이터로 인식합니다. 데이터프레임을 만든 후, CSV 파일로 저장할 수 있습니다. R 내장 함수인 write.csv()를 통해 데이..
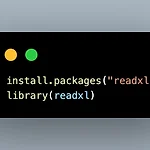 R - R 언어로 엑셀파일 불러오기(read_excel)
R - R 언어로 엑셀파일 불러오기(read_excel)
이번 포스트에선 R언어로 엑셀 불러오는 방법에 대해 알아보겠습니다. 먼저 엑셀 파일을 불러오기 위해선 패키지 설치가 필요합니다. 위와 같이 install.packages()를 통해 패키지 설치가 가능합니다. 엑셀 파일을 불러오기위해선 readxl 패키지가 필요합니다. 설치 후 library()를 통해 패키지를 불러옵니다. read_excel()를 통해 엑셀을 불러옵니다. 괄호 안에는 불러올려고 하는 파일의 경로를 ""와 함께 넣어줍니다. 만약 엑셀 파일 첫번째 행이 변수가 아닐 때는 read_excel() 괄호 안에 col_names = F를 함께 입력합니다. col_names = F은 첫 번째 행을 변수 명이 아닌 데이터로 인식해 불러오고 변수명은 '...숫자'로 자동 지정됩니다. 직접 코드로 확인해보..
 R - 데이터 프레임 만들기(data.frame(), $)
R - 데이터 프레임 만들기(data.frame(), $)
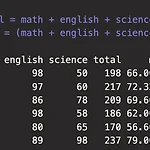
먼저 변수를 만들어 봅시다. 데이터 프레임을 만들 때는 data.frame() 을 이용합니다. 괄호 안에는 데이터 프레임을 구성할 변수를 나열합니다. df_exam 은 아래와 같습니다. 이번에는 데이터프레임에 각 학생의 성별을 추가하겠습니다. gender이라는 이름을 가진 list를 만든 후 df_exam에 data.frame()을 통해 데이터프레임을 생성합니다. 마찬가지로 View(df_exam)을 통해 아래와 같이 데이터프레임을 볼 수 있습니다. 이 데이터프레임을 분석해보겠습니다. mean()을 이용해 전체 학생의 과학 점수와, 영어 점수의 평균을 구해보겠습니다. 위와 같이 df_exam$english를 통해 df_exam 데이터 프레임 안의 english 변수에 접근할 수 있습니다. $은 데이터 프..
 네이버 부스트캠프 모각공 캠페인 10일차 - Sequential Models - RNN
네이버 부스트캠프 모각공 캠페인 10일차 - Sequential Models - RNN
모든 설명 및 자료의 출처는 네이버 부스트코스의 입니다. (https://www.boostcourse.org/onlyboostcampaitech3/joinLectures/329424) Sequential Models - RNN Sequential Model Naive sequence model Autoregressive model Markov model (first-order autoregressive model) Latent autoregressive model Recurrent Neural Network Short-term dependencies = RNN의 단점 , Short-term의 데이터만 주로 활용하고, Long-term data를 활용하긴 힘들다. Long-term dependencies ..
 네이버 부스트캠프 모각공 캠페인 10일차 - CNN-Convolution은 무엇인가?
네이버 부스트캠프 모각공 캠페인 10일차 - CNN-Convolution은 무엇인가?
모든 설명 및 자료의 출처는 네이버 부스트코스의 입니다. (https://www.boostcourse.org/onlyboostcampaitech3/joinLectures/329424) CNN-Convolution은 무엇인가? Convolution Continuous convolution Discrete convolution 2D image convolution Convolution 2D convolution RGB Image Convolution Stack of Convolution Convolution Neural Networks CNN consists of Convolution layer, pooling layer, and fully connected layer. Convolution and pool..