
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- r
- JavaScript
- summarise( )
- col_names
- 모각공
- dplyr
- Filter
- 정규표현식
- RNN
- Sequential Model
- convolution 역전파
- LinearNeuralNetwork
- regex
- 부스트캠프
- Beyond Linear Neural Networks
- 부스트캠프 aitech3기
- 네이버커넥트재단
- 자바스크립트
- Convolution
- Multi-Layer Perceptron
- 네이버커넥트
- NomadCoder
- aitech
- 베이즈통계학
- 생활코딩
- group_by( )
- 역전파알고리즘
- regular expression
- mutate( )
- 부스트캠프aitech3기
- Today
- Total
clear_uncertainty
네이버 부스트캠프 모각공 캠페인 7일차 - Pandas(2) 본문
네이버 부스트캠프 모각공 캠페인 7일차 - Pandas(2)
SOidentitiy 2021. 11. 16. 21:05
모든 설명 및 자료의 출처는 네이버 부스트코스의 <[부스트캠프 AI Tech 3기] Pre-Course>입니다.
(https://www.boostcourse.org/onlyboostcampaitech3/joinLectures/329424)
<꼭 알아야 하는 파이썬 기초 지식>
Pandas(2)
Groupby
SQL groupby 명령어와 같습니다.
split -> apply -> combine 과정을 거쳐 연산합니다
= index(key)가 같은 것끼리 묶어준 후 통계학함수를 거친 후 결과를 보여줍니다.
Hierachical index
groupby 명령의 결과물도 결국은 dataframe
두개의 column으로 groupby를 할 경우, index가 두개 생성
Hierarchical index - unstack()
group으로 묶여진 데이터를 matrix 형태로 전환

Index level을 변경할 수 있습니다.
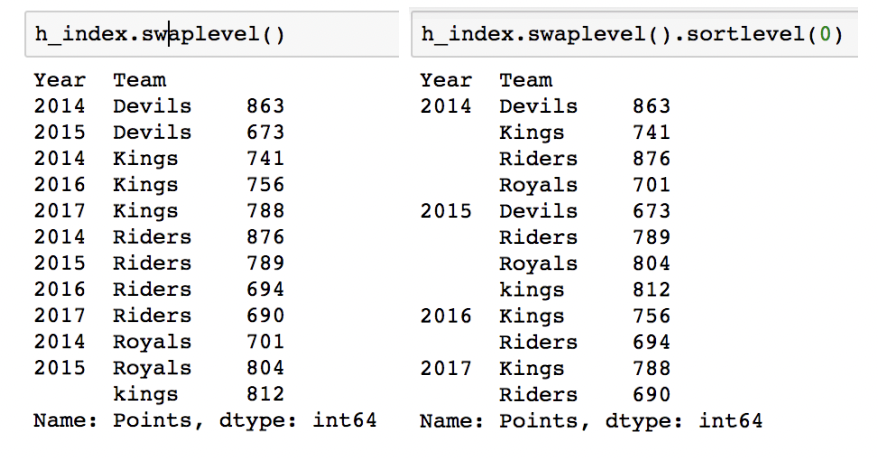
Hierarchical index - operations
Index level 을 기준으로 기본 연산 수행 가능
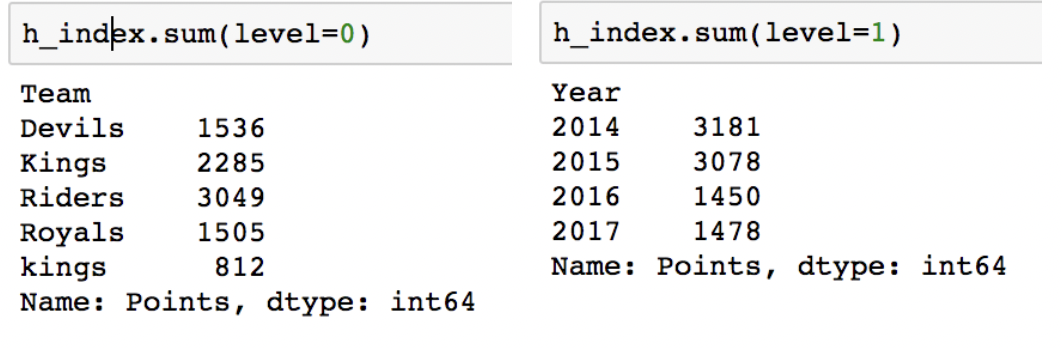
groupby - gropued
groupby에 의해 Split 된 상태를 추출 가능합니다.

특정 key값을 가진 그룹의 정보만 추출 가능합니다. (=get_group)

추출된 group 정보에는 세 가지 유형의 apply 가 가능합니다.
- Aggregation : 요약된 통계 정보를 추출
- Transformation : 해당 정보를 변환
- Filtration : 특정 정보를 제거하여 보여주는 필터링 기능
groupby - aggregation


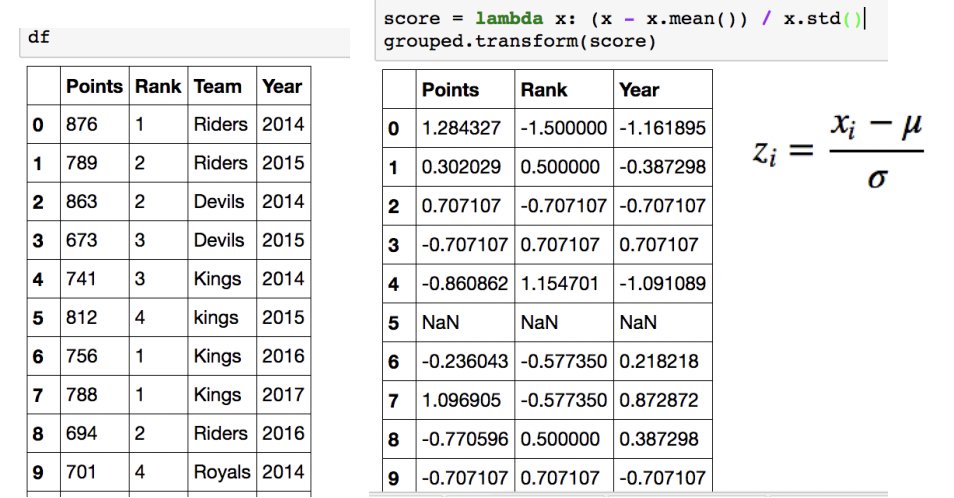
groupby - transformation

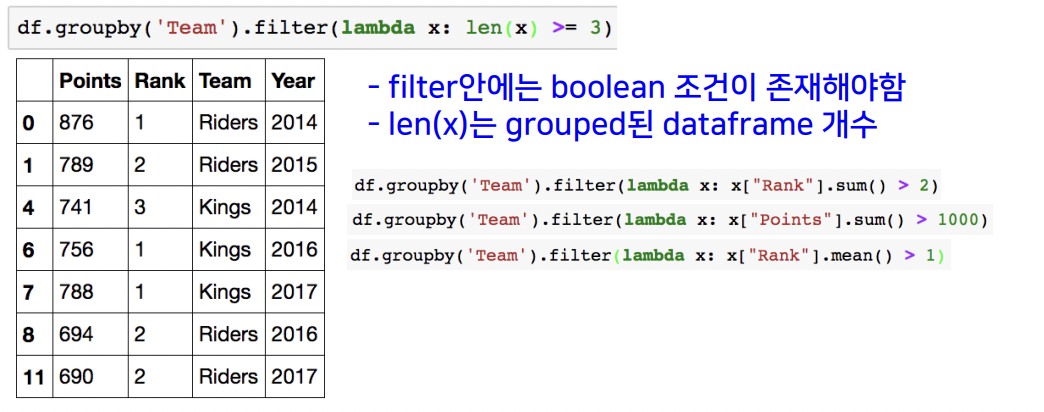
groupby - filter
특정 조건으로 데이터를 검색할 때 사용
Case study
Data : 시간과 데이터 종류가 정리된 통화량 데이터



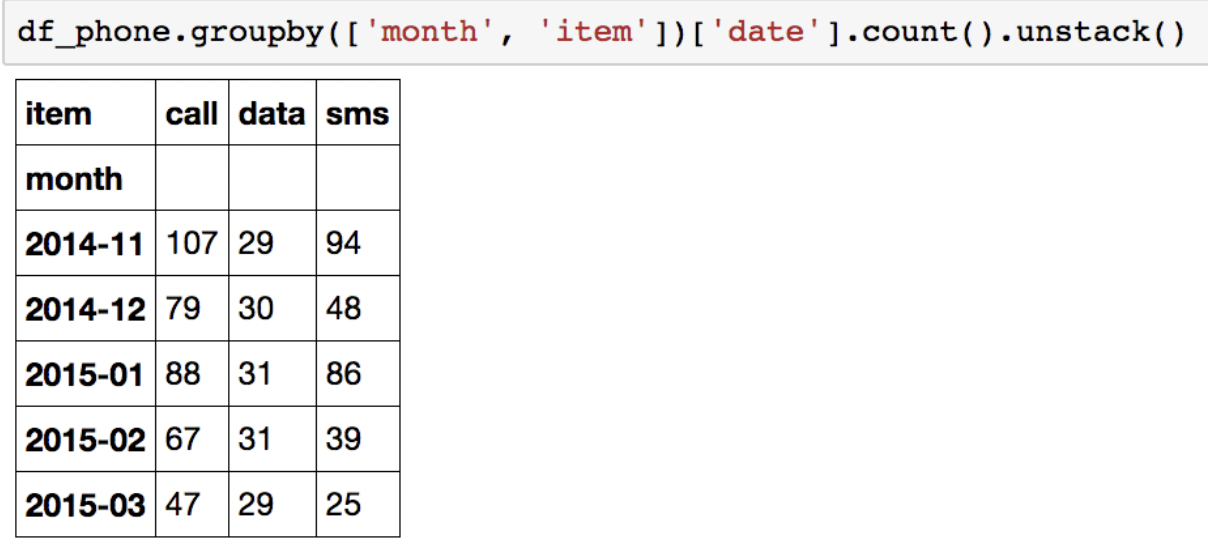


as_index = False 를 사용하면 month를 인덱스로 설정하지않습니다.
반대로, as_index=True를 사용하면 month를 index로 사용합니다.



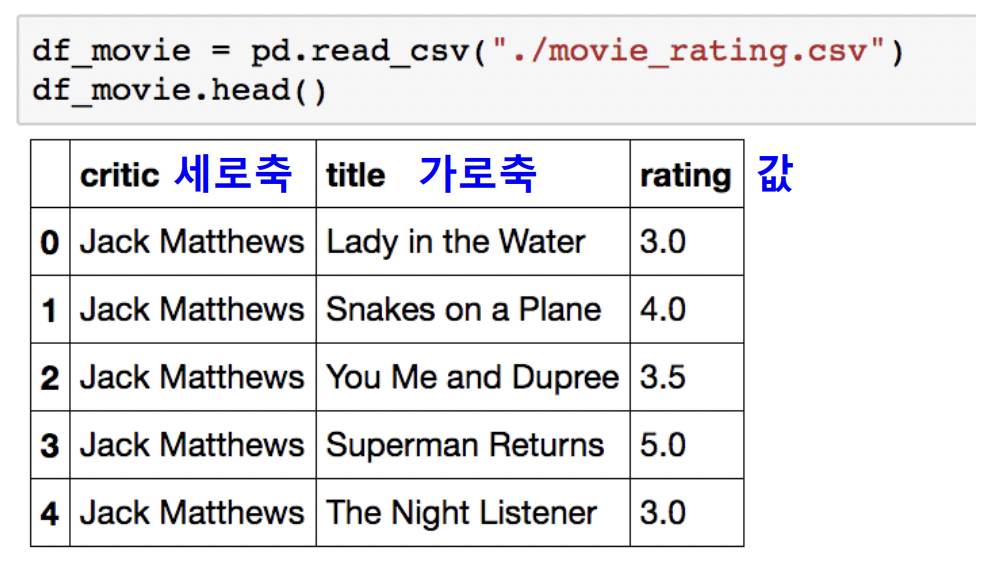
Pivot Table
우리가 엑셀에서 보던 것
Index 축은 groupby와 동일
Column에 추가로 labeling 값을 추가하여 Value에 numeric type 값을 aggregation 하는 형태


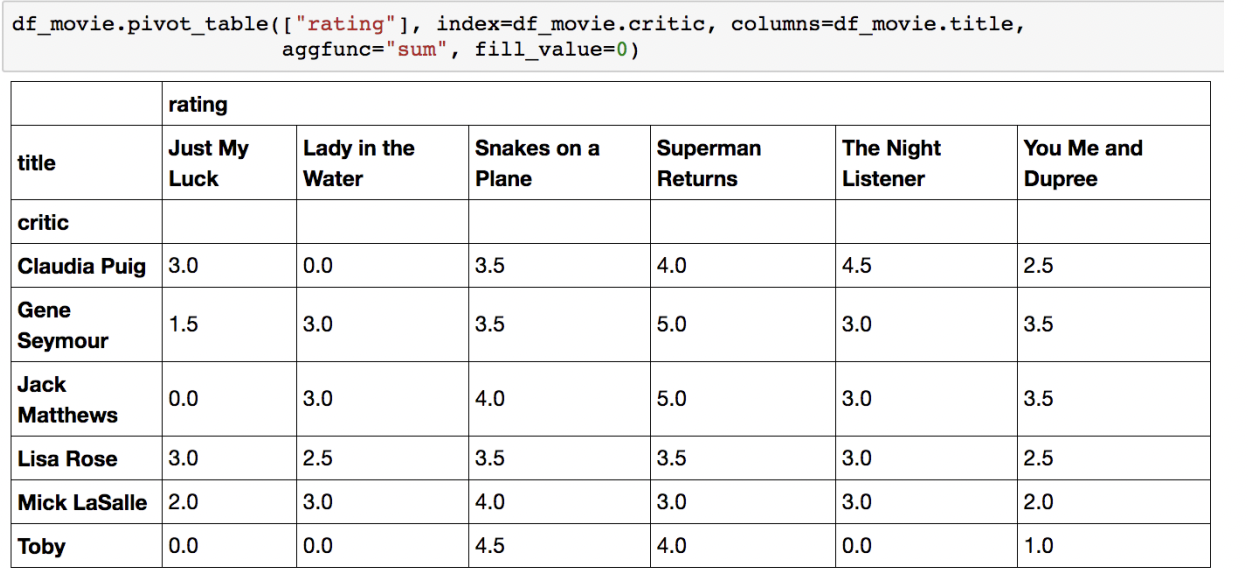
Crosstab
특히 두 칼럼에 교차 빈도, 비율, 덧셈 등을 구할 때 사용
Pivot table의 특수한 형태
User-Item Rating Matrix 등을 만들 때 사용 가능

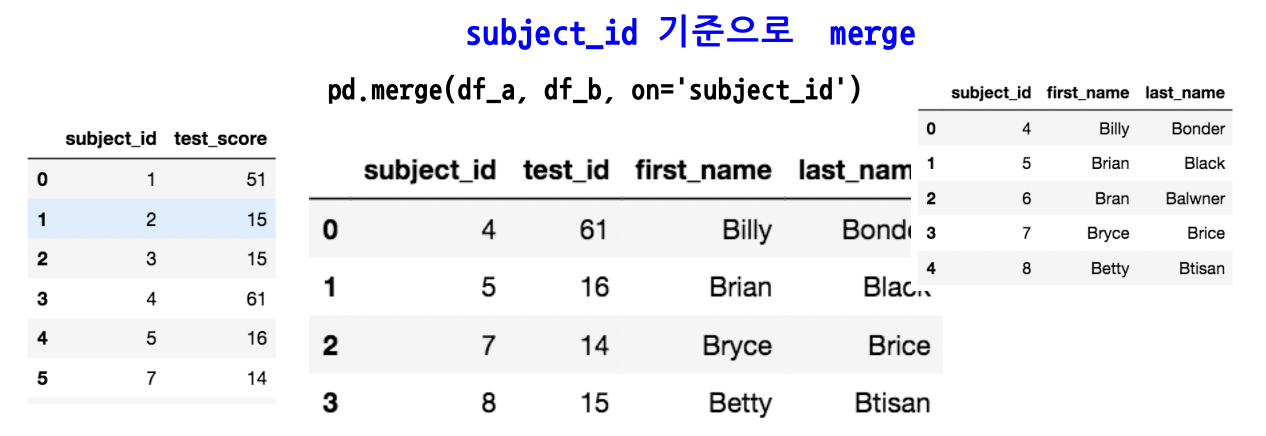
Merge & Concat
SQL에서 많이 사용하는 Merge와 같은 기능
두개의 데이터를 하나로 합침(무슨 기준으로 할 것이냐?)


join method

data

left join

right join
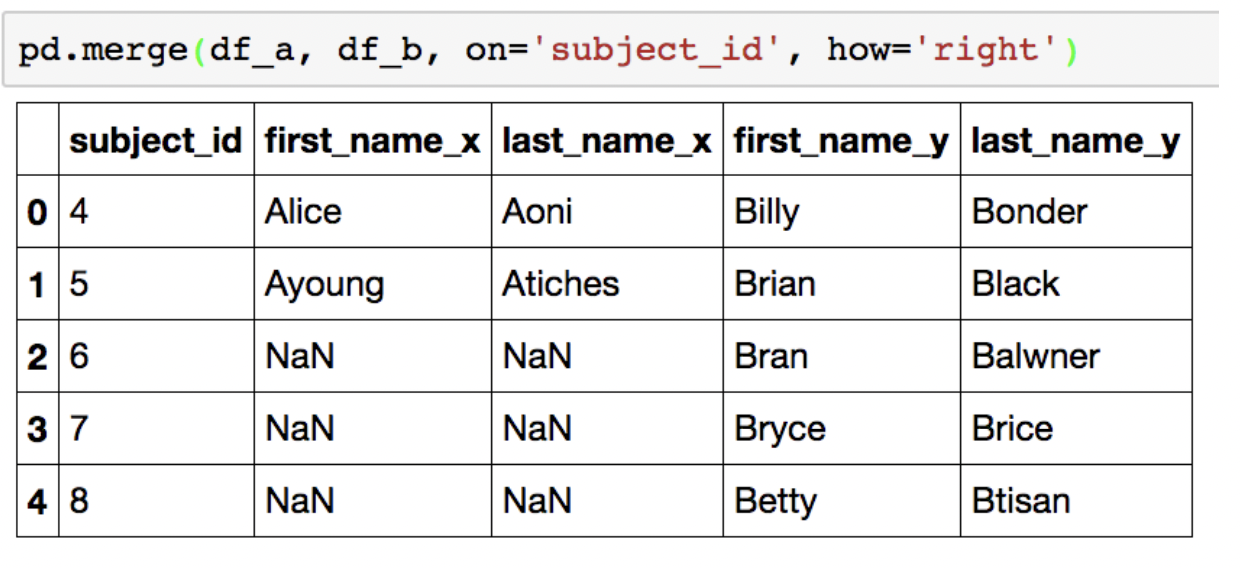
full(outer) join
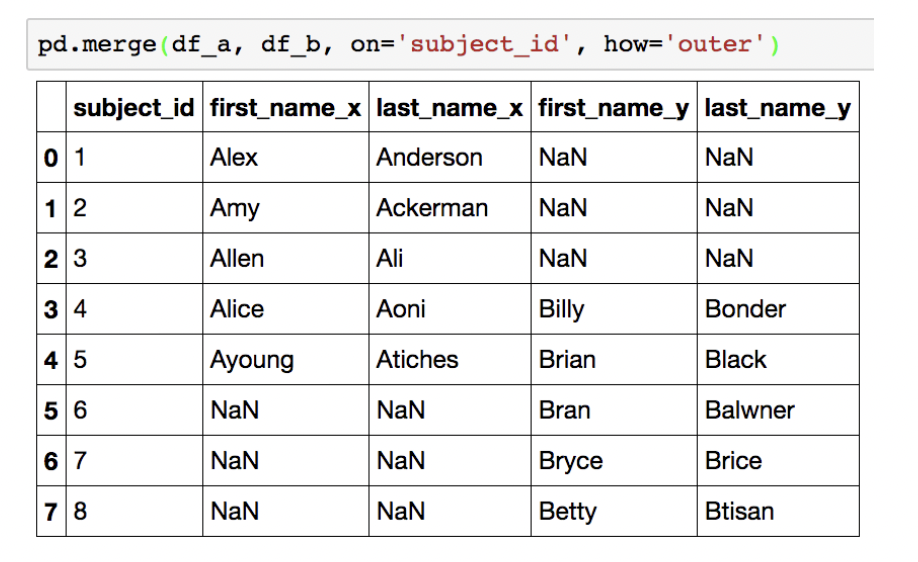
inner join

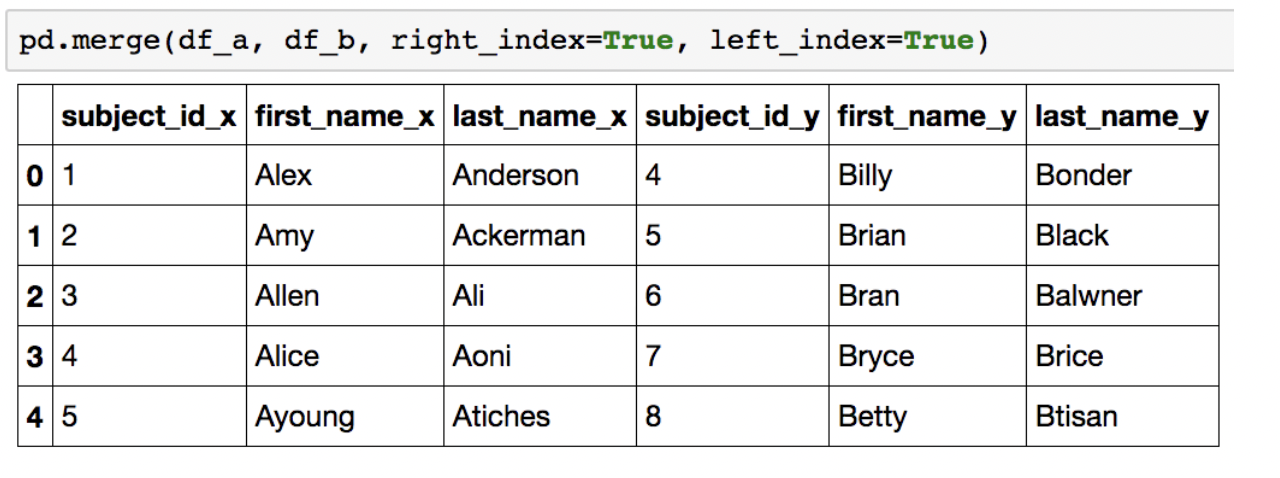
index based join
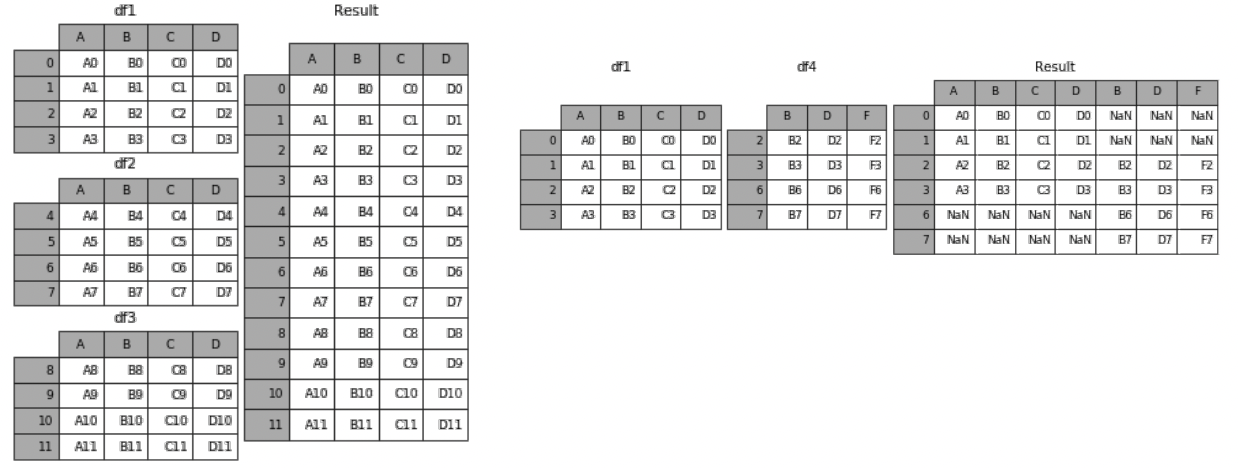
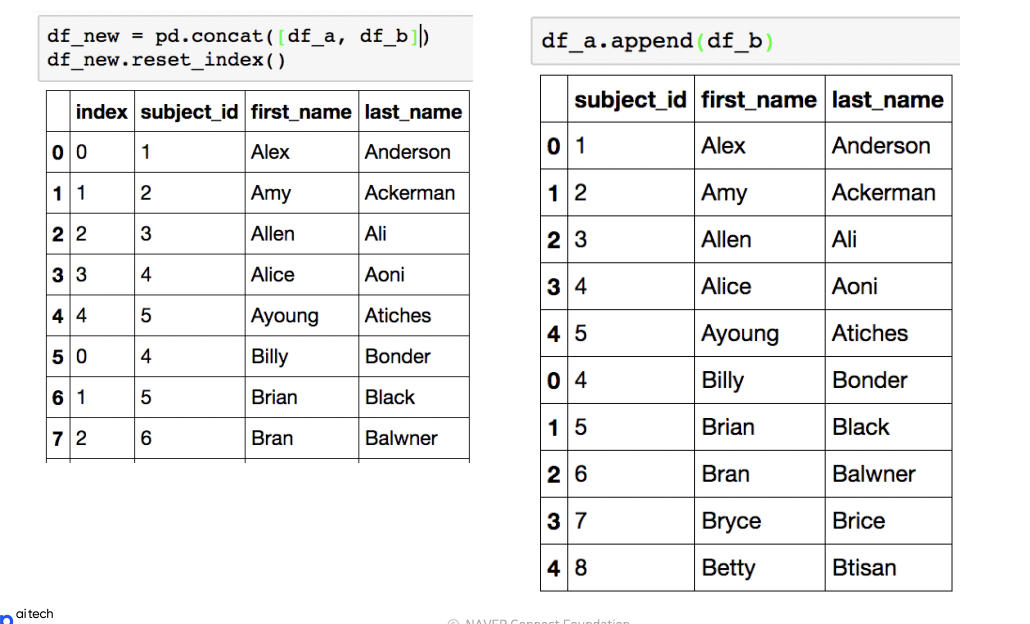
concat
같은 형태의 데이터를 붙이는 연산작업

persistence
Database connection Data loading 시 db connection 기능을 제공

XLS persistence
Dataframe 의 엑셀 추출 코드
Xls 엔진으로 openpyxls 또는 XlsxWrite 사용
Pickle persistence
가장 일반적인 python 파일 persistence
to_pickle, read_pickle 함수 사용

출처
[부스트캠프 AI Tech 3기] Pre-Course
www.boostcourse.org
'네이버 부스트캠프 - AI Tech 3rd > 꼭 알아야하는 파이썬 기초지식' 카테고리의 다른 글
| 네이버 부스트캠프 모각공 캠페인 6일차 - Pandas (0) | 2021.11.14 |
|---|---|
| 네이버 부스트캠프 모각공 캠페인 5일차 - Numerical Python - numpy (0) | 2021.11.12 |
| 네이버 부스트캠프 모각공 4일차 - Python Data Handling (0) | 2021.11.11 |
| 네이버 부스트캠프 모각공 3일차 - File/Exception/Log Handling (0) | 2021.11.10 |
| 네이버 부스트캠프 모각공 캠페인 3일차 - Module and Project (0) | 2021.11.10 |



